Math Word Problem Tutorial¶
Introduction¶
In this demo, we will have a closer look at how to apply Graph2Tree model to the task of math word problem automatically solving. Math word problem solving aims to infer reasonable equations from given natural language problem descriptions. It is important for exploring automatic solutions to mathematical problems and improving the reasoning ability of neural networks. In this demo, we use the Graph4NLP library to build a GNN-based math word problem (MWP) solving model.
The Graph2Tree model consists of:
graph construction module (e.g., node embedding based dynamic graph)
graph embedding module (e.g., undirected GraphSage)
predictoin module (e.g., tree decoder with attention and copy mechanisms)
The full example can be downloaded from Math word problem notebook.
As shown in the picture below, we firstly construct graph input from problem description by syntactic parsing (CoreNLP) and then represent the output equation with a hierarchical structure (Node “N” stands for non-terminal node).
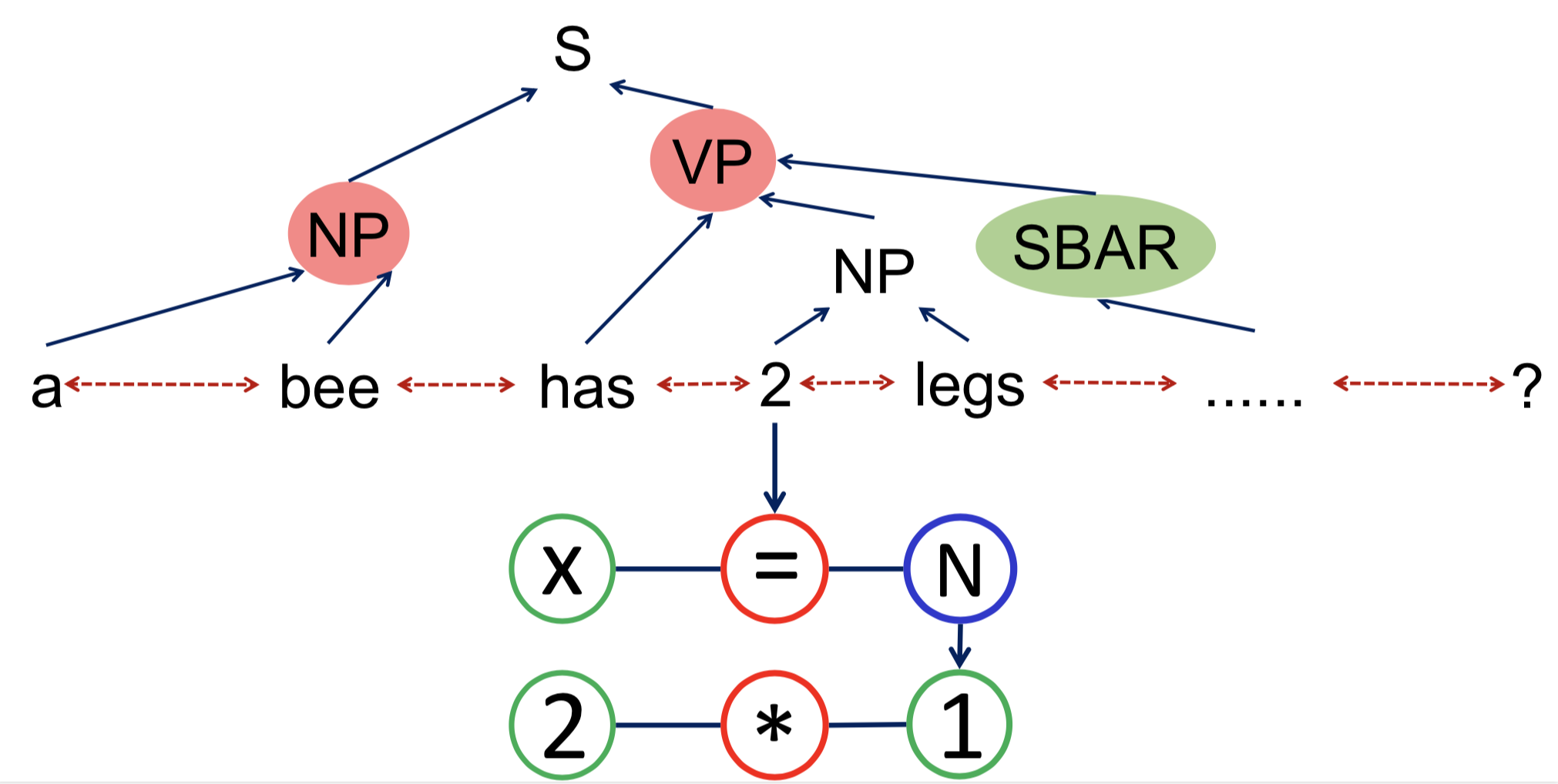
We will use the built-in Graph2Tree model APIs to build the model, and evaluate it on the Mawps dataset.
Environment setup¶
Create virtual environment
conda create --name graph4nlp python=3.7
conda activate graph4nlp
Install graph4nlp library
Clone the github repo
git clone -b stable https://github.com/graph4ai/graph4nlp.git
cd graph4nlp
Then run
./configure(or./configure.batif you are using Windows 10) to config your installation. The configuration program will ask you to specify your CUDA version. If you do not have a GPU, please choose ‘cpu’.
./configure
Finally, install the package
python setup.py install
Set up StanfordCoreNLP (for static graph construction only, unnecessary for this demo because preprocessed data is provided)
Download StanfordCoreNLP
Go to the root folder and start the server
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
Load the config file¶
from graph4nlp.pytorch.modules.config import get_basic_args
from graph4nlp.pytorch.modules.utils.config_utils import update_values, get_yaml_config
def get_args():
config = {'dataset_yaml': "./config.yaml",
'learning_rate': 1e-3,
'gpuid': 1,
'seed': 123,
'init_weight': 0.08,
'graph_type': 'static',
'weight_decay': 0,
'max_epochs': 20,
'min_freq': 1,
'grad_clip': 5,
'batch_size': 20,
'share_vocab': True,
'pretrained_word_emb_name': None,
'pretrained_word_emb_url': None,
'pretrained_word_emb_cache_dir': ".vector_cache",
'checkpoint_save_path': "./checkpoint_save",
'beam_size': 4
}
our_args = get_yaml_config(config['dataset_yaml'])
template = get_basic_args(graph_construction_name=our_args["graph_construction_name"],
graph_embedding_name=our_args["graph_embedding_name"],
decoder_name=our_args["decoder_name"])
update_values(to_args=template, from_args_list=[our_args, config])
return template
# show our config
cfg_g2t = get_args()
from pprint import pprint
pprint(cfg_g2t)
The config output¶
{'batch_size': 20,
'beam_size': 4,
'checkpoint_save_path': './checkpoint_save',
'dataset_yaml': './config.yaml',
'decoder_args': {'rnn_decoder_private': {'max_decoder_step': 35,
'max_tree_depth': 8,
'use_input_feed': True,
'use_sibling': False},
'rnn_decoder_share': {'attention_type': 'uniform',
'dropout': 0.3,
'fuse_strategy': 'concatenate',
'graph_pooling_strategy': None,
'hidden_size': 300,
'input_size': 300,
'rnn_emb_input_size': 300,
'rnn_type': 'lstm',
'teacher_forcing_rate': 1.0,
'use_copy': True,
'use_coverage': False}},
'decoder_name': 'stdtree',
'gpuid': 1,
'grad_clip': 5,
'graph_construction_args': {'graph_construction_private': {'as_node': False,
'edge_strategy': 'homogeneous',
'merge_strategy': 'tailhead',
'sequential_link': True},
'graph_construction_share': {'graph_type': 'dependency',
'port': 9000,
'root_dir': './data',
'share_vocab': True,
'thread_number': 4,
'timeout': 15000,
'topology_subdir': 'DependencyGraph'},
'node_embedding': {'connectivity_ratio': 0.05,
'embedding_style': {'bert_lower_case': None,
'bert_model_name': None,
'emb_strategy': 'w2v_bilstm',
'num_rnn_layers': 1,
'single_token_item': True},
'epsilon_neigh': 0.5,
'fix_bert_emb': False,
'fix_word_emb': False,
'hidden_size': 300,
'input_size': 300,
'num_heads': 1,
'rnn_dropout': 0.1,
'sim_metric_type': 'weighted_cosine',
'smoothness_ratio': 0.1,
'sparsity_ratio': 0.1,
'top_k_neigh': None,
'word_dropout': 0.1}},
'graph_construction_name': 'dependency',
'graph_embedding_args': {'graph_embedding_private': {'activation': 'relu',
'aggregator_type': 'lstm',
'bias': True,
'norm': None,
'use_edge_weight': False},
'graph_embedding_share': {'attn_drop': 0.0,
'direction_option': 'undirected',
'feat_drop': 0.0,
'hidden_size': 300,
'input_size': 300,
'num_layers': 1,
'output_size': 300}},
'graph_embedding_name': 'graphsage',
'graph_type': 'static',
'init_weight': 0.08,
'learning_rate': 0.001,
'max_epochs': 20,
'min_freq': 1,
'pretrained_word_emb_cache_dir': '.vector_cache',
'pretrained_word_emb_name': None,
'pretrained_word_emb_url': None,
'seed': 123,
'share_vocab': True,
'weight_decay': 0}
Import packages¶
import copy
import torch
import random
import argparse
import numpy as np
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm.notebook import tqdm
from graph4nlp.pytorch.data.data import to_batch
from graph4nlp.pytorch.datasets.mawps import MawpsDatasetForTree
from graph4nlp.pytorch.modules.graph_construction import DependencyBasedGraphConstruction
from graph4nlp.pytorch.modules.graph_embedding import *
from graph4nlp.pytorch.models.graph2tree import Graph2Tree
from graph4nlp.pytorch.modules.utils.tree_utils import Tree, prepare_oov
from utils import convert_to_string, compute_tree_accuracy
Build the model¶
class Mawps:
def __init__(self, opt=None):
super(Mawps, self).__init__()
self.opt = opt
seed = self.opt["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if self.opt["gpuid"] == -1:
self.device = torch.device("cpu")
else:
self.device = torch.device("cuda:{}".format(self.opt["gpuid"]))
self.use_copy = self.opt["decoder_args"]["rnn_decoder_share"]["use_copy"]
self.use_share_vocab = self.opt["graph_construction_args"]["graph_construction_share"]["share_vocab"]
self.data_dir = self.opt["graph_construction_args"]["graph_construction_share"]["root_dir"]
self._build_dataloader()
self._build_model()
self._build_optimizer()
def _build_dataloader(self):
para_dic = {'root_dir': self.data_dir,
'word_emb_size': self.opt["graph_construction_args"]["node_embedding"]["input_size"],
'topology_builder': DependencyBasedGraphConstruction,
'topology_subdir': self.opt["graph_construction_args"]["graph_construction_share"]["topology_subdir"],
'edge_strategy': self.opt["graph_construction_args"]["graph_construction_private"]["edge_strategy"],
'graph_type': 'static',
'dynamic_graph_type': self.opt["graph_construction_args"]["graph_construction_share"]["graph_type"],
'share_vocab': self.use_share_vocab,
'enc_emb_size': self.opt["graph_construction_args"]["node_embedding"]["input_size"],
'dec_emb_size': self.opt["decoder_args"]["rnn_decoder_share"]["input_size"],
'dynamic_init_topology_builder': None,
'min_word_vocab_freq': self.opt["min_freq"],
'pretrained_word_emb_name': self.opt["pretrained_word_emb_name"],
'pretrained_word_emb_url': self.opt["pretrained_word_emb_url"],
'pretrained_word_emb_cache_dir': self.opt["pretrained_word_emb_cache_dir"]
}
dataset = MawpsDatasetForTree(**para_dic)
self.train_data_loader = DataLoader(dataset.train, batch_size=self.opt["batch_size"], shuffle=True,
num_workers=0,
collate_fn=dataset.collate_fn)
self.test_data_loader = DataLoader(dataset.test, batch_size=1, shuffle=False, num_workers=0,
collate_fn=dataset.collate_fn)
self.valid_data_loader = DataLoader(dataset.val, batch_size=1, shuffle=False, num_workers=0,
collate_fn=dataset.collate_fn)
self.vocab_model = dataset.vocab_model
self.src_vocab = self.vocab_model.in_word_vocab
self.tgt_vocab = self.vocab_model.out_word_vocab
self.share_vocab = self.vocab_model.share_vocab if self.use_share_vocab else None
def _build_model(self):
'''For encoder-decoder'''
self.model = Graph2Tree.from_args(self.opt, vocab_model=self.vocab_model)
self.model.init(self.opt["init_weight"])
self.model.to(self.device)
def _build_optimizer(self):
optim_state = {"learningRate": self.opt["learning_rate"], "weight_decay": self.opt["weight_decay"]}
parameters = [p for p in self.model.parameters() if p.requires_grad]
self.optimizer = optim.Adam(parameters, lr=optim_state['learningRate'], weight_decay=optim_state['weight_decay'])
def train_epoch(self, epoch):
loss_to_print = 0
num_batch = len(self.train_data_loader)
for step, data in tqdm(enumerate(self.train_data_loader), desc=f'Epoch {epoch:02d}', total=len(self.train_data_loader)):
batch_graph, batch_tree_list, batch_original_tree_list = data['graph_data'], data['dec_tree_batch'], data['original_dec_tree_batch']
batch_graph = batch_graph.to(self.device)
self.optimizer.zero_grad()
oov_dict = prepare_oov(
batch_graph, self.src_vocab, self.device) if self.use_copy else None
if self.use_copy:
batch_tree_list_refined = []
for item in batch_original_tree_list:
tgt_list = oov_dict.get_symbol_idx_for_list(item.strip().split())
tgt_tree = Tree.convert_to_tree(tgt_list, 0, len(tgt_list), oov_dict)
batch_tree_list_refined.append(tgt_tree)
loss = self.model(batch_graph, batch_tree_list_refined if self.use_copy else batch_tree_list, oov_dict=oov_dict)
loss.backward()
torch.nn.utils.clip_grad_value_(
self.model.parameters(), self.opt["grad_clip"])
self.optimizer.step()
loss_to_print += loss
return loss_to_print/num_batch
def train(self):
best_acc = -1
best_model = None
print("-------------\nStarting training.")
for epoch in range(1, self.opt["max_epochs"]+1):
self.model.train()
loss_to_print = self.train_epoch(epoch)
print("epochs = {}, train_loss = {:.3f}".format(epoch, loss_to_print))
if epoch > 15:
val_acc = self.eval(self.model, mode="val")
if val_acc > best_acc:
best_acc = val_acc
best_model = self.model
self.eval(best_model, mode="test")
best_model.save_checkpoint(self.opt["checkpoint_save_path"], "best.pt")
def eval(self, model, mode="val"):
model.eval()
reference_list = []
candidate_list = []
data_loader = self.test_data_loader if mode == "test" else self.valid_data_loader
for data in tqdm(data_loader, desc="Eval: "):
eval_input_graph, batch_tree_list, batch_original_tree_list = data['graph_data'], data['dec_tree_batch'], data['original_dec_tree_batch']
eval_input_graph = eval_input_graph.to(self.device)
oov_dict = prepare_oov(eval_input_graph, self.src_vocab, self.device)
if self.use_copy:
reference = oov_dict.get_symbol_idx_for_list(batch_original_tree_list[0].split())
eval_vocab = oov_dict
else:
reference = model.tgt_vocab.get_symbol_idx_for_list(batch_original_tree_list[0].split())
eval_vocab = self.tgt_vocab
candidate = model.translate(eval_input_graph,
oov_dict=oov_dict,
use_beam_search=True,
beam_size=self.opt["beam_size"])
candidate = [int(c) for c in candidate]
num_left_paren = sum(1 for c in candidate if eval_vocab.idx2symbol[int(c)] == "(")
num_right_paren = sum(1 for c in candidate if eval_vocab.idx2symbol[int(c)] == ")")
diff = num_left_paren - num_right_paren
if diff > 0:
for i in range(diff):
candidate.append(self.test_data_loader.tgt_vocab.symbol2idx[")"])
elif diff < 0:
candidate = candidate[:diff]
ref_str = convert_to_string(reference, eval_vocab)
cand_str = convert_to_string(candidate, eval_vocab)
reference_list.append(reference)
candidate_list.append(candidate)
eval_acc = compute_tree_accuracy(candidate_list, reference_list, eval_vocab)
print("{} accuracy = {:.3f}\n".format(mode, eval_acc))
return eval_acc
Run and get results¶
a = Mawps(cfg_g2t)
best_acc = a.train()
Graph construction |
GNN embedding |
Model |
Accuracy |
|---|---|---|---|
Dependency graph |
Graphsage |
Graph2tree |
78.0 |