Dataset workflow¶
To use a dataset for experiment, we first need to get the original data files from online access. Then some pre-processing may need to be performed on the raw data to get some processed files. The processed data will be loaded to memory for training. During training, the whole dataset is sliced into small batches and fed to the model iteratively. According to the workflow described above, a typical dataset workflow consists of 4 steps: downloading raw data, pre-processing raw data, loading data and iterating over it. The following figure illustrates this workflow:
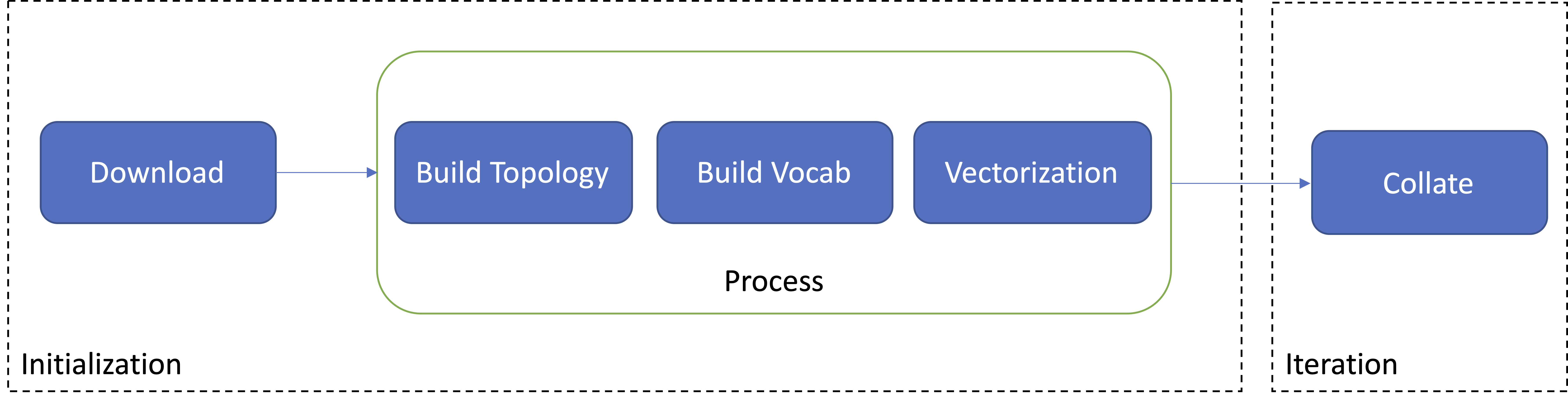
Dataset Workflow¶
For the first two steps, we need to specify the raw data and processed data file names. In Graph4NLP’s convention, similar to
PyG, the raw data file is stored under the raw directory under
the dataset’s root directory. Similarly, the processed data file is stored under the processed sub-directory.
class Dataset:
@property
def raw_dir(self) -> str:
"""The directory where the raw data is stored."""
return os.path.join(self.root, 'raw')
@property
def processed_dir(self) -> str:
return os.path.join(self.root, 'processed', self.topology_subdir)
On initializing a dataset object, the Dataset class first checks if the raw files exist. If not, then the _download()
routine is triggered to download the raw data files.
After checking the raw data, Dataset then checks if the processed files exist. If not, the _process() routine is
triggered to process the raw data and save the processed files locally.
After these two steps, the remaining works can be reduced to a typical torch.Dataset and torch.DataLoader workflow.