Chapter 5.2 Standard Tree Decoder¶
The output of many NLP applications (i.e., semantic parsing, code generation, and math word problem) contain structural information. For example, the output in math word problem is a mathematical equation, which can be expressed naturally by the data structure of the tree. To model these kinds of outputs, tree decoders are widely adopted. Tree decoders can be divided into two main parts: DFS (depth-first search) based tree decoder, and BFS (breadth-first search) based tree decoder. We mainly implement BFS based tree decoder here. Specifically, we give a simple example on how StdTreeDecoder is initialized as follows,
import torch
import torch.nn as nn
from graph4nlp.pytorch.modules.config import get_basic_args
from graph4nlp.pytorch.modules.utils.config_utils import update_values, get_yaml_config
from graph4nlp.pytorch.datasets.jobs import JobsDatasetForTree
from graph4nlp.pytorch.modules.utils.tree_utils import Vocab
from graph4nlp.pytorch.modules.prediction.generation.TreeBasedDecoder import StdTreeDecoder
# get your vocab_model, batch_graph, and tgt_tree_batch
dec_word_emb = nn.Embedding(out_vocab.embeddings.shape[0],
out_vocab.embeddings.shape[1],
padding_idx=0,
_weight=torch.from_numpy(out_vocab.embeddings).float())
decoder = StdTreeDecoder(attn_type="uniform", embeddings=dec_word_emb, enc_hidden_size=300,
dec_emb_size=out_vocab.embedding_dims, dec_hidden_size=300,
output_size=out_vocab.vocab_size,
criterion=nn.NLLLoss(ignore_index=0, reduction='none'),
teacher_force_ratio=1.0, use_copy=False, max_dec_seq_length=50,
max_dec_tree_depth=5, tgt_vocab=out_vocab)
predicted = decoder(batch_graph=batch_graph, tgt_tree_batch=tgt_tree_batch)
Implementation details¶
What is the tree decoding process¶
In the BFS-based tree decoding approach, we represent all subtrees as non-terminal nodes. Then we divide the whole tree structure into multiple “sequences” from top to bottom according to the non-terminal nodes, which is shown in code below,
def get_dec_batch(dec_tree_batch, batch_size, device, form_manager):
queue_tree = {}
for i in range(1, batch_size+1):
queue_tree[i] = []
queue_tree[i].append({"tree": dec_tree_batch[i-1], "parent": 0, "child_index": 1})
cur_index, max_index = 1, 1
dec_batch = {}
# max_index: the max number of sequence decoder in one batch
while (cur_index <= max_index):
max_w_len = -1
batch_w_list = []
for i in range(1, batch_size+1):
w_list = []
if (cur_index <= len(queue_tree[i])):
t = queue_tree[i][cur_index - 1]["tree"]
for ic in range(t.num_children):
if isinstance(t.children[ic], Tree):
w_list.append(4)
queue_tree[i].append({"tree": t.children[ic], "parent": cur_index, "child_index": ic + 1})
else:
w_list.append(t.children[ic])
if len(queue_tree[i]) > max_index:
max_index = len(queue_tree[i])
if len(w_list) > max_w_len:
max_w_len = len(w_list)
batch_w_list.append(w_list)
dec_batch[cur_index] = torch.zeros(
(batch_size, max_w_len + 2), dtype=torch.long)
for i in range(batch_size):
w_list = batch_w_list[i]
if len(w_list) > 0:
for j in range(len(w_list)):
dec_batch[cur_index][i][j+1] = w_list[j]
if cur_index == 1:
dec_batch[cur_index][i][0] = 1
else:
dec_batch[cur_index][i][0] = form_manager.get_symbol_idx('(')
dec_batch[cur_index][i][len(w_list) + 1] = 2
dec_batch[cur_index] = to_cuda(dec_batch[cur_index], device)
cur_index += 1
return dec_batch, queue_tree, max_index
We then use sequence decoding to generate the tree structure in order. And for each sequence decoding process, we will feed the embedding of its parent node and sibling node as auxiliary input.
The figure below is an example for tree decoding process, where nodes like S1 , S2 stand for sub-tree nodes, and once a sub-tree node generated, decoder will start a new branch for a new descendant decoding process. The number stands for the order of different branching decoding processes.
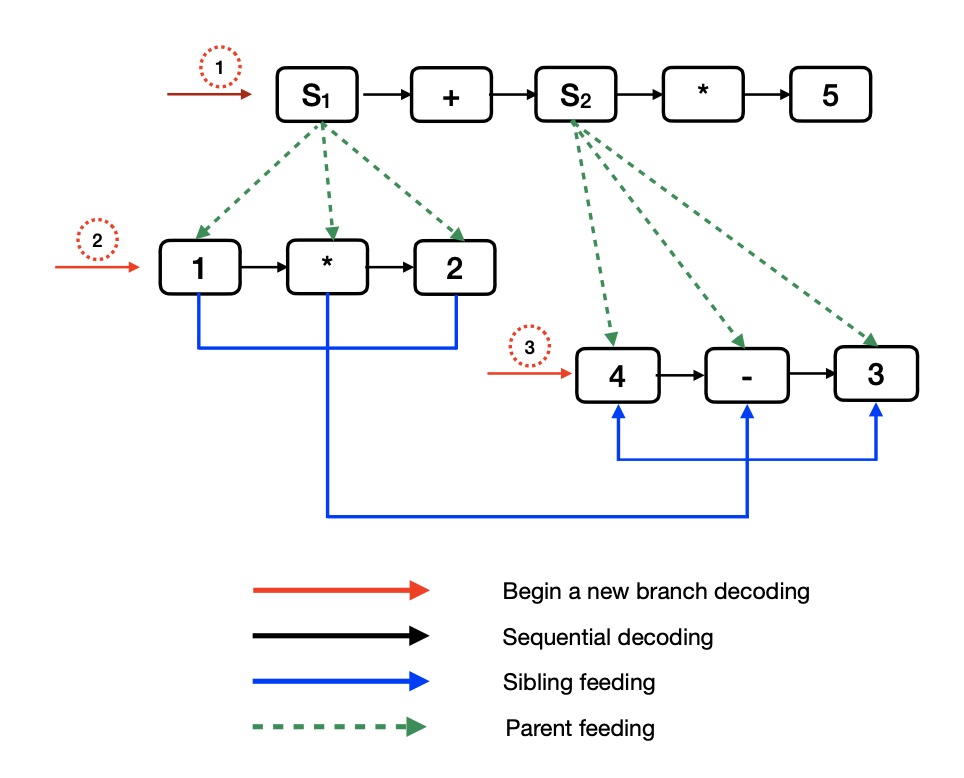
And we give a rough code snippet about how tree decoding is completed.
cur_index = 0
while (cur_index <= max_index):
if cur_index > max_dec_tree_depth:
break
...
# get parent and sibling embeddings.
# do sequence decoding.
...
cur_index = cur_index + 1
Where max_index is the number of non-terminal nodes and max_dec_tree_depth is the maximum number of non-terminal nodes allowed.
Copy and separate attention¶
StdTreeDecoder employ copy and separate attention mechanism to enhance the overall Graph2Tree model. We show how copy is used in StdTreeDecoder here. Both StdTreeDecoder and StdRNNDecoder use separate attention mechanism, it has been explained in Chapter 5.1 Standard RNN Decoder. So we will not go into detail here.
For copy mechanism, it helps model to copy words directly from input, and computed as,
\(p(w) = p_{gen} p_{softmax}(w) + (1 - p_{gen}) p_{copy}(w)\).
We refer to the implement of pointer-network. Technically, for a certain mini-batch graphdata, we firstly extend the original vocabulary to a full-vocabulary containing all words (including out-of-vocabulary (oov) words) in the mini-batch:
oov_dict = copy.deepcopy(src_vocab)
token_matrix = []
for n in batch_graph.node_attributes:
node_token = n['token']
# Pick out all out-of-vocabulary (oov) words in the mini-batch graphdata.
if (n.get('type') == None or n.get('type') == 0) and oov_dict.get_symbol_idx(
node_token) == oov_dict.get_symbol_idx(oov_dict.unk_token):
# Add them into oov vocab model.
oov_dict.add_symbol(node_token)
token_matrix.append(oov_dict.get_symbol_idx(node_token))
return oov_dict
After that, the decoder learns the conditional probability of an output sequence with elements that are discrete tokens corresponding to positions in an input sequence. Code snippets as follows help with how it works.
if self.use_copy:
pgen_collect = [dec_emb, hidden, attn_ptr]
# the probability of copying a word from the source
prob_ptr = torch.sigmoid(self.ptr(torch.cat(pgen_collect, -1)))
# the probability of generating a word over the standard softmax on vocabulary model.
prob_gen = 1 - prob_ptr
gen_output = torch.softmax(decoder_output, dim=-1)
ret = prob_gen * gen_output
need_pad_length = oov_dict.get_vocab_size() - self.vocab.get_vocab_size()
output = torch.cat((ret, ret.new_zeros((batch_size, need_pad_length))), dim=1)
# attention scores
ptr_output = dec_attn_scores
output.scatter_add_(1, src_seq, prob_ptr * ptr_output)
decoder_output = output
else:
decoder_output = torch.softmax(decoder_output, dim=-1)
The returned decoder_output is a distribution over the extend dictionary oov_dict if copy is adopted. Users can set use_copy to True to use this feature. And the oov vocabulary must be passed when utilizing it.